Kubernetes Operator
Operators are software extensions that run on kubernetes. Operators, which we also call software operators, are application specific controllers that create, manage, and configure instances of complex stateful applications using Kubernetes APIs. Working by using Kubernetes APIs means that these controllers can monitor the cluster, change pods and services, scale, and call endpoints of running applications according to the customized rules written in them.
The operators build upon basic kubernetes source and controller concepts, but also includes domain or application specific knowledge to automate common tasks.
Actions of the operators include,
- Deployment on demand
- Backup application state or return from backup
- Manage application code upgrades due to database schema or configuration changes
- Manage Kubernetes upgrades
- Auto Scaling
It is easy to manage and scale stateless applications such as Web App, Web API, mobile backend on Kubernetes. It is more complex to manage stateful applications such as monitoring systems, cache and database. We need domain specific knowledge to make correct scaling, upgrades and configuration changes without data loss or interruption in stateful applications. We ensure correct management of applications by removing this application specific operational domain knowledge in operators in Kubernetes.

Elasticsearch Official and Zalando Operators
Before going into the details of the operators, let us briefly touch upon the terminology of Elasticsearch. In Elasticsearch, the term Index corresponds to Database in relational databases, the term Shard corresponds Physical Partion, and the term Replica corresponds to keeping a copy of the data on a different machine. In the table below, we see an example of how one replica of 3 shards is distributed within 3 data nodes of Elasticsearch.
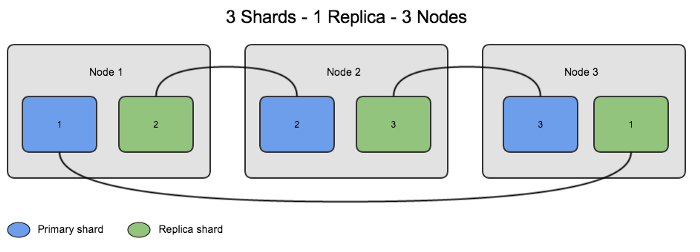
Now back to the operators, there are many operators for Elasticsearch that are written to solve different needs. We will be illustrating the uses of operators by examining the Official Elasticsearch operator and the operator of Zalando.
Elastic Cloud on Kubernetes (ECK)
Elastic Cloud on Kubernetes, which is official operator of Elasticsearh, automates the preparation, loading and management of Elasticsearch, Kibana, and APM Server based on the operator pattern.
Features
- Elasticsearch, Kibana and APM Server installation
- TLS Certificates management
- Safe Elasticsearch cluster configuration & topology changes
- Persistent volumes usage
- Custom node configuration and attributes
- Secure settings keystore updates
We usually deploy operators by adding Custom Resource Definition (CRD) and its combined controllers to kubernetes. Here, too, we will take a closer look at the operator logic by examining the Elasticsearch official operator and the CRD setup example.
We are able to provide operator and CRD setups with role definitions by applying a single patch, and at the end of the work, we see that 3 separate CRDs have been created for Elasticsearch, Kibana and APM installations.
kubectl apply -f https://download.elastic.co/downloads/eck/1.0.1/all-in-one.yamlcustomresourcedefinition.apiextensions.k8s.io/apmservers.apm.k8s.elastic.co created
customresourcedefinition.apiextensions.k8s.io/elasticsearches.elasticsearch.k8s.elastic.co created
customresourcedefinition.apiextensions.k8s.io/kibanas.kibana.k8s.elastic.co created
clusterrole.rbac.authorization.k8s.io/elastic-operator created
clusterrolebinding.rbac.authorization.k8s.io/elastic-operator created
namespace/elastic-system created
statefulset.apps/elastic-operator created
serviceaccount/elastic-operator created
validatingwebhookconfiguration.admissionregistration.k8s.io/elastic-webhook.k8s.elastic.co configured
service/elastic-webhook-server created
secret/elastic-webhook-server-cert created
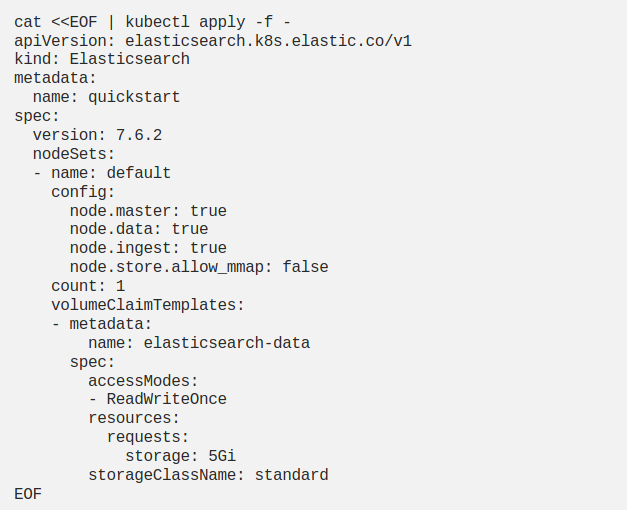
It is now very simple to install Elasticsearch using the elasticsearch CRD we have installed above, it is sufficient to apply the following patch, which we say that Elasticsearch will run on a single node and its data will be kept persistent. Here, we need to pay attention to give the definition of Volume Claim Templates with the name elasticsearch-data. If the default storageclass is installed in your cluster, we ensure that Elasticsearch data is stored as persistent without the need to create another definition.
We can check the Elasticsearch installation, the versions, numbers and health of installed elastic nodes as follows.

Another advantage of the operator is the ability to update the version with minimum interruption in case there are sufficient resources on the cluster. When we update the number of nodecounts in yaml, where Elasticsearch will be installed on a single node, the operator provides version updates without the need for manual action.
Zalando Es-operator
Zalando, a leading company in the online fashion industry of Europe, uses Elasticsearch in its e-commerce website infrastructure. Zalando has developed the Elasticsearch operator to scale according to the load that occurs in certain periods and to manage version updates more effectively.
To install Zalando’s Elasticsearch operator, we follow a similar way to the Official Elasticsearch Operator installation.
While the Zalando ES-Operator does not interfere with the management of the master node in the Elasticsearch cluster, it manages the data nodes in order to facilitate the upgrade process and provides convenience in version updates. We create the Elasticsearch data node using the CRD definitions we created.

If we try to load the Elasticsearch cluster with helm for example without using an operator, we see that both master and data nodes are deployed as statefulset. In the Zalando operator, we see that it consists of ElasticsearchDataSets where the master node is defined as statefulset and the data nodes are defined as CRD.

Version Upgrade
In order to better explain the benefit of the version update feature, I would like to talk about the difficulties we had in trying to install Elasticsearch with Helm. The statefulsets controlled the pods in the Elasticsearch cluster, and in version upgrades, the periods were both very long, and sometimes the data nodes remained in terminating status. The reason for this was that version updates made with Statefulset worked as follows:
- Before the Elasticsearch data node is killed, all the data it contains is moved to other elasticsearch data nodes,
- Then, in the new version, the elasticsearch data node is deployed and the data transferred to other nodes is moved to the new elasticsearch data node.
The Zalando Operator, on the other hand, simplified the version updates as follows, and developed the solution that will enable the version updates to be made in a shorter and more effective manner.
- Before the data node in the old version is killed, the elasticsearch data node in the new version is deployed.
- Before the elasticsearch data node in the old version is killed, the data on it is transferred to the elasticsearch data nod in the new version.
Scaling
Kubernetes ensures automatic scaling of pods in replication controller, deployment, replicaset or statefulset with Horizontal Pod Autoscaler which is basically based on CPU data but also supports different custom metrics.
The Zalando Operator's scaling feature also works based on the CPU consumption collected from pods where ElasticsearchDataSet is running. Before going into the details of how the scaling is carried out, I wanted to add an example of the CRD definition created for the Elasticsearch data node.
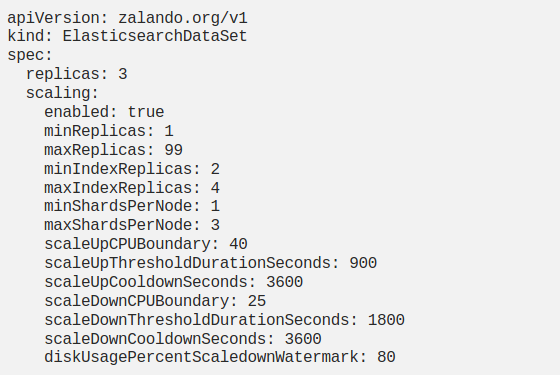
How does Scaling Work?
For an index with 6 shards, let us examine the steps of scaling according to the increase in CPU consumption for the cluster of Elasticseach data nodes working according to the above definition.
(1 Index 6 Shards — minReplicas = 2, maxReplicas=4, minShardsPerNode=1, maxShardsPerNode=3, targetCPU: 40%)
In the cluster, the amount of resources needed for initial deployment is determined according to the maxShardsPerNode parameter (3 copies of index x 6 shards = 18 shards / 3-per-node => 6 nodes)
- 1. When the CPU consumption exceeds 40%, the number of nodes is increased by reducing ShardsPerNode, the number of shards per node (18 shards / 2 per-node => 9 nodes)
- 2. When the CPU consumption exceeds 40% again, the number of nodes continues to increase until the ShardsPerNode value reaches the value of minShardsPerNode. (18 shards / 1 per-node => 18 nodes)
- 3. If CPU consumption continues to increase and again goes over 40% and if the minShardsPerNode value is reached, the number of index replicaIndexReplicas in the Nodes is increased and scaling continues by adding the required nodes. In our example, the value of minIndexReplicas was 2, when we increase it to 3, the number of shards increases from 18 to 24. (24 shards / 1 per node => 24 nodes)
- 4. When the CPU consumption reaches 40% again, the IndexReplicas value is increased again and this time the maxIndexReplicas value is reached. (36 shards / 1 per node => 36 nodes)
After this point, ElasticsearchDataSet cannot be scaled up according to the CRD definition, but as the CPU consumption decreases, the steps taken are recycled in order to scale down.
(Here, you can view the presentation of Zalando Es-Operator at KubeCon 2019)
Operator Framework
Until this point, we have touched on what operators are through 2 different examples. Now let us examine the benefits provided by the operator framework, where we can manage the operations with operators.
The Operator Framework is an open source toolkit to manage Kubernetes native applications, called operators, in an effective, automated, and scalable way. Its objective is to bring together the expertise and knowledge of the Kubernetes community in a single Project to be used as a standard application suite and to simplify application development for Kubernetes.
The Operator Framework consists of 5 components:
-
1.
Operator SDK
provided to develop Operators without needing to know Kubernetes API complexity
- 2.
Operator Lifecycle Manager (OLM)
which manages installation and controls processes such as upgrades of the operators running on Kubernetes.
- 3.
Operator Registry, which stores Operator metadata, ClusterServiceVersions (CSVs) and Custom Resource Definitions (CRDs), runs on kubernetes or Openshift clusters to provide Operator Catalog data to OLM
- 4.
OperatorHub
(comes installed on OpenShift Container Platform), the web portal where cluster admins can find operators to upload to the cluster.
- 5.
Operator Metering, which scales usage of operators by providing customized services
Similar to the Elasticsearch operator examples that I have reviewed in this article, there are operators written to facilitate the management operations of many infrastructures and applications on kubernetes. We can easily access the operators we need on OperatorHub. We can install the operators either manually as we have done above or via OLM.
If we want to automate specific tasks in our own applications, we can create operators like Zalando has done. At this point, we can use the Operator SDK of the Operator Framework, as it provides ease of development.

